

Artikel uit Kennisgeving, jrg. 4, nr 2, juli 1991, pp. 12-15

Reinforcement Learning
In de serie machine learning is het deze keer de beurt aan Aad Hogervorst. In dit artikel wordt reinforcement learning beschreven, een algoritme met als kenmerk dat terugkoppeling plaatsvindt op basis van zeer weinig informatie. Deze informatie komt bovendien pas na meerdere tijdsstappen ter beschikking.
Inleiding.
Er bestaan diverse typen neurale netwerken. Het meest populaire neurale netwerk is het type dat leert d.m.v. het zogenaamde backpropagationalgoritme. Dit algoritme is reeds in Kennisgeving (september 1990) beschreven door Bert Grootjans en gaat er van uit dat concrete voorbeelden aan het netwerk worden aangeboden. Elk voorbeeld bestaat uit een input (een patroon van activiteitswaarden van de inputneuronen) in combinatie met de gewenste output (activiteitswaarden van de outputneuronen). Het backpropagationalgoritme past bij elke presentatie van een voorbeeld de verbindingsgewichten tussen de neuronen aan. Op deze wijze lijkt de output van het netwerk steeds meer op de gewenste output.
Echter niet voor alle situaties is het populaire backpropagationalgoritme bruikbaar. Dit is bijvoorbeeld het geval als een neuraal netwerk voor elk van een aantal achtereenvolgens aangeboden inputs een output moet genereren voordat duidelijk is of een beoogd doel bereikt wordt of niet. ln plaats van telkens de gewenste output ter beschikking te hebben, is nu slechts bekend of de serie outputs als geheel goed genoeg was of niet. Dat levert niet veel informatie op voor het algoritme dat de verbindingsgewichten zodanig moet aanpassen dat het netwerk de volgende keer een beter resultaat geeft. Het is enerzijds onbekend welke outputs een (on)gunstige invloed op het totale resultaat hebben gehad en anderzijds is voor elk van de geleverde outputs onbekend welke outputneuronen wel of niet een goede waarde hadden. Dat op basis van gebrekkige informatie toch leeralgoritmen mogelijk zijn, wordt geïllustreerd door het volgende voorbeeld.
Rode of groene plant
In dit voorbeeld beweegt een zeer simpele "muis" zich voort met een constante snelheid in een vlakke ruimte, die omgeven is door een zwart gekleurde wand. In deze ruimte zijn verder nog twee planten aanwezig, namelijk een groene en een rode. De groene plant is lekker, de rode vies. De muis heeft twee ogen, met in elk oog twee lichtgevoelige cellen, één voor groen licht en één voor rood licht. Figuur 1 toont de vaste kijkrichtingen van de ogen, en de gevoeligheid van de ogen als functie van de invalshoek van het licht. Deze gevoeligheid is voor beide kleuren gelijk.
|
|
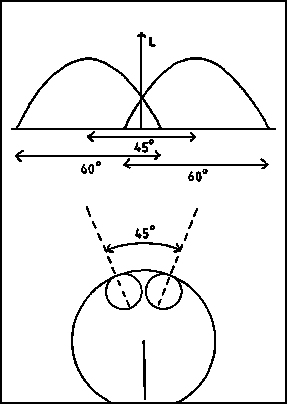 Afbeelding 1: De vaste kijkrichtingen van de ogen van de muis en de gevoeligheid (L, voor beide kleuren gelijk) van de beide ogen als functie van de hoek van de lichtinval.
Afbeelding 1: De vaste kijkrichtingen van de ogen van de muis en de gevoeligheid (L, voor beide kleuren gelijk) van de beide ogen als functie van de hoek van de lichtinval.Elke lichtgevoelige cel is verbonden met een inputneuron van het neurale netwerk van de muis (zie figuur 2). Het signaal dat een lichtgevoelige cel afgeeft aan het corresponderende neuron is evenredig met de hoeveelheid licht die het detecteert. Het neurale netwerk van de muis heeft dus vier inputneuronen. Deze inputneuronen zijn door middel van vaste (niet door het leeralgoritme te beïnvloeden) koppelingsgewichten (+0.5 of -0.5) verbonden met de neuronen in de tweede laag. De koppelingsgewichten tussen de neuronen in de tweede laag en de outputneuronen hebben een beginwaarde 0. Het leeralgoritme moet ervoor zorgen dat deze koppelingsgewichten zinvolle waarden krijgen.
|
|
 Afbeelding 2: Het neurale netwerk van de muis. De koppelingsgewichten zijn aangegeven met pijlen en de verbindingslijnen tussen de neuronen (vierkanten).
Afbeelding 2: Het neurale netwerk van de muis. De koppelingsgewichten zijn aangegeven met pijlen en de verbindingslijnen tussen de neuronen (vierkanten).Muisbesturing
Het neurale netwerk is een zogenaamd feedforward netwerk. Dat wil zeggen dat de activiteiten van de neuronen in de tweede laag alleen afhangen van de activiteitswaarden van de inputneuronen, en dat de activiteitswaarden van de outputneuronen alleen afhangen van de activiteitswaarden van de neuronen in de tweede laag. De activiteitswaarde van elk neuron wordt op de gebruikelijke manier berekend: de activiteitswaarden van de relevante neuronen in de erboven gelegen laag worden vermenigvuldigd met de corresponderende koppelingsgewichten, en de som hiervan geeft na transformatie de gezochte activiteitswaarde.
Deze transformatie wordt verzorgd door de zogenaamde "neuron transfer functie" (zie figuur 3). De neuron transfer functie zorgt ervoor dat de activiteitswaarden altijd tussen -1 en +1 liggen. Alleen voor de outputneuronen wordt nog een random getal tussen -0.05 en +0.05 opgeteld bij de som voordat de transformatie plaatsvindt. Voor elk inputneuron geeft het signaal van de corresponderende lichtgevoelige cel na transformatie door de neuron transfer functie de activiteitswaarde. Omdat de hoeveelheid licht die op een lichtgevoelige cel valt per definitie positief is, is de activiteitswaarde van een inputneuron altijd positief.
|
|
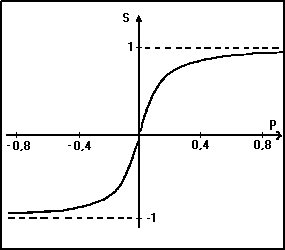 Afbeelding 3: De "neuron transfer functie" (S) geeft de activiteitswaarde van een neuron als funktie van de gewogen som (P) van de activiteitswaarden van de neuronen in de erboven liggende laag.
Afbeelding 3: De "neuron transfer functie" (S) geeft de activiteitswaarde van een neuron als funktie van de gewogen som (P) van de activiteitswaarden van de neuronen in de erboven liggende laag.De richting waarin de muis zich beweegt hangt af van de activiteitswaarden van de twee outputneuronen van het netwerk. Als het linker outputneuron een grotere activiteitswaarde heeft dan de rechter, dan stuurt de muis zijn richting bij naar links; als het rechter outputneuron een grotere activiteitswaarde heeft, dan draait de muis naar rechts. De mate van bijsturing is groter naarmate het verschil tussen beide activiteitswaarden groter is.
Simulatie.
De simulatie van de verplaatsingen van de muis gaat als volgt. Eerst wordt berekend hoeveel licht er op de vier lichtgevoelige cellen in de ogen van de muis valt. Op basis daarvan worden de activiteitswaarden van de neuronen in de drie opeenvolgende lagen berekend, om vervolgens de aanpassing van de bewegingsrichting van de muis te kunnen bepalen. Als laatste stap wordt de muis in de nieuwe richting gedraaid, en een zekere afstand in die richting verplaatst. In de nieuwe positie wordt weer berekend hoeveel licht er op de lichtgevoelige cellen valt, etc. Als de muis een wand bereikt, wordt de bewegingsrichting zo veranderd, dat de muis als het ware door de wand teruggekaatst wordt. Hetzelfde wordt gedaan als de muis een plant bereikt: de muis kaatst dan als een rubber balletje verder.
Aanpassing koppelingsgewichten
Het is de bedoeling dat het leeralgoritme de koppelingsgewichten tussen de neuronen in de tweede laag en de outputneuronen zodanig wijzigt, dat de muis zoveel mogelijk naar de lekkere groene plant toegaat, en de vieze rode plant mijdt. Het leeralgoritme moet dit doen op basis van summiere informatie. Alleen als de muis een van beide planten bereikt, is bekend of de voorafgaande acties van het netwerk een gunstig (groene plant bereikt) of een ongunstig resultaat (rode plant bereikt) hebben. In het eerste geval wordt de muis als het ware beloond (lekker), en in het tweede geval gestraft (vies). Deze informatie wordt in het Engels "reinforcement" (in het Nederlands: bekrachtiging) genoemd, en het leren op basis hiervan "reinforcement learning" (leren op basis van bekrachtiging).
Het leeralgoritme dat de koppelingsgewichten in de goede richting wijzigt wordt als volgt verklaard. Terwijl de muis zich verplaatst, wordt voor elk te wijzigen koppelingsgewicht een soort correlatie bijgehouden van de activiteiten van de beide neuronen. Deze correlatie is positief als de beide activiteitswaarden overwegend hetzelfde teken hebben, negatief als ze overwegend tegengesteld van teken zijn. De correlatie wordt berekend door in elke simulatiestap de oude waarde van de correlatie te vermenigvuldigen met een positief getal kleiner dan 1 (0.9), en vervolgens het produkt van beide activiteitswaarden erbij op te tellen. Op deze manier wordt de correlatie vooral door de meest recente stappen bepaald.
Als de muis een plant bereikt, wordt elk vrij koppelingsgewicht gewijzigd door er het produkt van de betreffende correlatie en een klein positief getal (0.01) bij op te tellen (groene plant) of van af te trekken (rode plant). In het eerste geval zal de kans groter zijn dat in het vervolg de correlaties hetzelfde teken hebben als op dit moment, en zal de kans dat de muis nogmaals naar de groene plant loopt groter zijn. Hierbij zijn vooral de koppelingsgewichten betrokken die met de groene kleur te maken hebben, omdat voornamelijk deze kleur is waargenomen vlak voor het bereiken van de groene plant. In het tweede geval is de kans juist kleiner geworden dat de correlaties weer hetzelfde zullen worden, en zal de kans op hetzelfde resultaat (de rode plant bereiken) kleiner zijn. Hierbij zijn vooral de "rode" koppelingsgewichten betrokken. Het resultaat van het leeralgoritme is dat de muis een steeds sterkere neiging krijgt om naar de groene plant toe te gaan, en om de rode plant te mijden.
Kanttekeningen
Omdat de muis op een gegeven moment nauwelijks meer de rode plant bereikt, zullen de koppelingsgewichten die betrekking hebben op deze kleur niet sterk meer wijzigen. De koppelingssterkten die met de groene kleur te maken hebben, veranderen echter steeds sterker: de bij deze koppelingsgewichten behorende correlaties zullen steeds sterker worden, en de groene plant wordt steeds vaker bereikt. Het gevolg van het onbegrensde groeien van de koppelingsgewichten is dat de richtingsveranderingen zo groot worden, dat de muis de groene plant telkens uit het oog verliest, en de groene plant wordt dan steeds minder bereikt. Deze tekortkoming van het leeralgoritme wordt in de simulatie gemaskeerd door de koppelingsgewichten te begrenzen tussen -0.5 en +0.5.
Na de hierboven gegeven beschrijving van het leeralgoritme zal het duidelijk zijn waarom gekozen is om de activiteitswaarden van de outputneuronen mede te laten bepalen door de random getallen tussen -0.05 en +0.05. Zonder deze ruis zouden de activiteitswaarden van de outputneuronen steeds 0 zijn omdat de koppelingsgewichten tussen deze neuronen en de neuronen in de tweede laag startwaarden 0 hebben. Dit betekent dat de correlaties steeds 0 zouden blijven en er dus geen wijzigingen van de koppelingssterkten zouden plaats vinden.
De tweede laag neuronen geeft eigenlijk een soort vertaling van de oorspronkelijke input, en zijn dus eigenlijk de echte inputneuronen. Met betrekking tot het leren is het netwerk dus eigenlijk een netwerk met alleen input- en outputneuronen. Het leren is in een dergelijk netwerk een stuk makkelijker dan in een netwerk waarin verborgen neuronen (neuronen die geen input- of outputneuronen zijn) aanwezig zijn, maar de mogelijkheden ervan zijn beperkter. Een netwerk met alleen input- en outputneuronen kan bijvoorbeeld nooit leren om wel naar groene en rode planten toe te gaan, maar niet naar een bruine plant (of een plant met zowel rode als groene blaadjes). Deze handicap wordt wel het XOR-probleem genoemd (naar de wiskundige formule die dit keuzevoorschrift weergeeft: eXclusive OR).
Aad Hogervorst was al in 1991 actief in de werkgroep Neurale Netwerken. Het programma van zijn hand, waarin de in dit artikel beschreven muis gesimuleerd werd (MOUSE8.EXE) was destijds tesamen met de Pascal source verkrijgbaar op een van de AIgg PD diskettes.




