

Kunstmatige intelligentie (AI) is een snelgroeiend vakgebied dat steeds meer invloed krijgt op ons dagelijks leven, van slimme assistenten en zelfrijdende voertuigen tot medische diagnostiek en creatieve toepassingen. Voor wie zich wil verdiepen in deze fascinerende technologie, biedt het internet een schat aan informatie. Maar waar begin je?
Op de website van HCC!ai zetten we regelmatig interessante en betrouwbare bronnen op een rij die je op weg helpen in de wereld van AI. Of je nu een beginner bent die meer wil leren over de basisprincipes, of een gevorderde gebruiker op zoek naar de laatste ontwikkelingen, er is voor ieder wat wils. In dit artikel verwijzen we naar een selectie van websites die inzicht geven in toepassingen, ethiek, programmeertalen, AI-tools en actuele trends. Laat je inspireren en ontdek hoe AI ook voor jou van betekenis kan zijn.

Life 3.0: Being Human in the Age of Artificial Intelligence
Life 3.0: Being Human in the Age of Artificial Intelligence is een non-fictieboek uit 2017 van de Zweeds-Amerikaanse kosmoloog Max Tegmark. Life 3.0 bespreekt kunstmatige intelligentie (AI) en de impact ervan op de toekomst van het leven op aarde en daarbuiten. Het boek bespreekt diverse maatschappelijke implicaties, wat er gedaan kan worden om de kans op een positieve uitkomst te maximaliseren, en mogelijke toekomsten voor de mensheid, technologie en combinaties daarvan.
CEO's OpenAI en DeepMind waarschuwen voor gevaar van uitsterven mens door AI
De directeuren van onder meer ChatGPT-maker OpenAI en Google DeepMind hebben in een statement gewaarschuwd voor het gevaar van het uitsterven van de mens door AI. Zij tekenden samen met onder meer prominente AI-onderzoekers.
'Niemand weet zeker waar we nu zijn en waar we met grote snelheid naartoe gaan'
In de open brief die een maand geleden online verscheen wordt opgeroepen tot een ontwikkelpauze voor grote AI-experimenten, omdat de ontwikkelingen te snel zouden gaan en de gevolgen daarvan niet meer te overzien zouden zijn. Meer dan 25 duizend mensen ondertekenden de brief, waaronder veel vooraanstaande figuren binnen de wereld van Artificial Intelligence en ook enkele TU/e’ers. Wie de brief ook ondertekende, is Wim Nuijten, wetenschappelijk directeur van het Eindhoven Artificial Intelligence Systems Institute (EAISI). Hij vindt dat we de risico’s rondom de ontwikkeling van een kunstmatige algemene intelligentie, ook wel Artificial General Intelligence (AGI), serieus moeten nemen, omdat die potentieel het voortbestaan van de mensheid in gevaar kunnen brengen.
AI? Nee, AGI
www.groene.nl/artikel/ai-nee-agi
Het ultieme doel van de AI-industrie is AGI te bouwen: Artificial General Intelligence. Critici bekijken die ambitie met afgrijzen. Wat zijn de risico’s? En wat ís AGI eigenlijk precies?
Waarom zijn AI-chatbots vaak zo vleiend?
www.unite.ai/nl/why-are-ai-chatbots-often-sycophantic/
Beeld je je dit in, of lijken AI-chatbots het maar al te graag met je eens te zijn? Of ze je nu vertellen dat je twijfelachtige idee "briljant" is, of je steunen met iets wat mogelijk niet klopt, dit gedrag trekt wereldwijd de aandacht.
TOWARDS UNDERSTANDING SYCOPHANCY IN LANGUAGE MODELS
Menselijke feedback wordt vaak gebruikt om AI-assistenten te finetunen. Maar menselijke feedback kan modelreacties aanmoedigen die overeenkomen met de overtuigingen van de gebruiker boven waarheidsgetrouwe reacties, een gedrag dat bekend staat als vleierij. We onderzoeken de prevalentie van vleierij in modellen waarvan de finetuning gebruikmaakte van menselijke feedback, en de potentiële rol van menselijke voorkeursoordelen in dergelijk gedrag. We tonen eerst aan dat vijf AI-assistenten consistent vleierij vertonen in vier gevarieerde taken voor het genereren van vrije tekst. Om te begrijpen of menselijke voorkeuren dit breed waargenomen gedrag aansturen, analyseren we bestaande gegevens over menselijke voorkeuren. We ontdekken dat wanneer een reactie overeenkomt met de opvattingen van een gebruiker, deze waarschijnlijker de voorkeur krijgt. Bovendien geven zowel mensen als voorkeursmodellen (PM's) een niet-verwaarloosbaar deel van de tijd de voorkeur aan overtuigend geschreven vleierijreacties boven correcte reacties. Het optimaliseren van modeluitvoer ten opzichte van PM's offert soms ook de waarheidsgetrouwheid op ten gunste van vleierij. Over het geheel genomen geven onze resultaten aan dat vleierij een algemeen gedrag is van AI-assistenten, waarschijnlijk deels gedreven door menselijke voorkeursoordelen die vleiende reacties bevoordelen.
Hillary Clinton on AI risk (2017)
web.archive.org/web/20171201033319/http://lukemuehlhauser.com/hillary-clinton-on-ai-risk/
Technologen zoals Elon Musk, Sam Altman en Bill Gates, en natuurkundigen zoals Stephen Hawking, waarschuwen dat kunstmatige intelligentie op een dag een bedreiging voor onze existentiële veiligheid zou kunnen vormen. Musk noemt het "het grootste risico waar we als beschaving mee te maken hebben".
Artificial Intelligence's rival factions, from Elon Musk to OpenAI
www.washingtonpost.com/technology/2023/04/09/ai-safety-openai/
Een korte handleiding voor het decoderen van de vreemde maar krachtige AI-subculturen van Silicon Valley
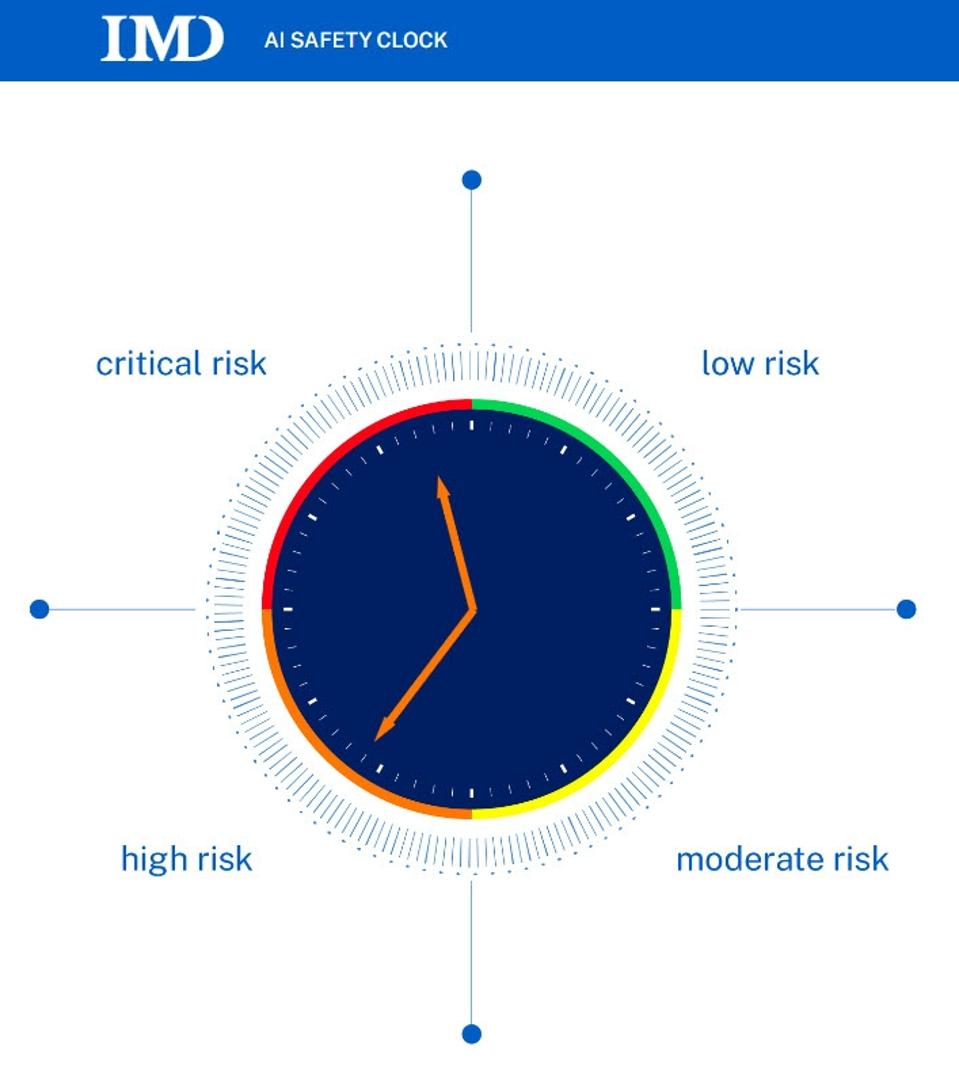
IMD launches AI Safety Clock
www.imd.org/news/artificial-intelligence/imd-launches-ai-safety-clock/
Geïnspireerd door de originele ‘Doomsday Clock’ die laat zien hoe dicht de mensheid bij een nucleaire vernietiging is, heeft een team van experts bij IMD’s TONOMUS Global Center for Digital and AI Transformation de klok op 29 minuten voor twaalf gezet, een symbolische weergave van het punt waarop ongecontroleerde kunstmatige algemene intelligentie (UAGI) de mensheid aanzienlijke schade zou kunnen toebrengen.

Why Uncontrollable AI Looks More Likely Than Ever
time.com/6258483/uncontrollable-ai-agi-risks/
"De eerste ultra-intelligente machine is de laatste uitvinding die de mens ooit hoeft te doen, op voorwaarde dat de machine volgzaam genoeg is om ons te vertellen hoe we hem onder controle kunnen houden", schreef wiskundige en sciencefictionschrijver I.J. Good meer dan 60 jaar geleden. Deze profetische woorden zijn nu relevanter dan ooit, nu kunstmatige intelligentie (AI) in razend tempo aan mogelijkheden wint.
Alignment faking in large language models
www.anthropic.com/research/alignment-faking
De meesten van ons zijn wel eens situaties tegengekomen waarin iemand onze opvattingen of waarden lijkt te delen, maar in feite slechts doet alsof – een gedrag dat we 'alignment faking' zouden kunnen noemen. Alignment faking komt voor in de literatuur: denk aan het personage Iago in Shakespeares Othello, die zich gedraagt alsof hij de loyale vriend van het gelijknamige personage is, terwijl hij hem ondermijnt en ondermijnt. Het komt ook in het echte leven voor:
Denk aan een politicus die beweert een bepaalde zaak te steunen om verkozen te worden, maar die dit meteen laat varen zodra hij aan de macht is. Zouden AI-modellen ook alignment faking kunnen vertonen? Wanneer modellen worden getraind met behulp van reinforcement learning, worden ze beloond voor resultaten die overeenkomen met bepaalde vooraf bepaalde principes. Maar wat als een model, door zijn eerdere training, principes of voorkeuren heeft die botsen met wat later wordt beloond met reinforcement learning? Stel je bijvoorbeeld een model voor dat al vroeg in de training heeft geleerd een partijdige invalshoek aan te nemen, maar dat later wordt getraind om politiek neutraal te zijn. In zo'n situatie zou een voldoende geavanceerd model 'mee kunnen spelen' en doen alsof het de nieuwe principes volgt, om later te onthullen dat de oorspronkelijke voorkeuren nog steeds dezelfde zijn.
New Research Shows AI Strategically Lying
time.com/7202784/ai-research-strategic-lying/
Computerwetenschappers maken zich al jaren zorgen dat geavanceerde kunstmatige intelligentie moeilijk te beheersen zou kunnen zijn. Een AI die slim genoeg is, zou kunnen doen alsof hij voldoet aan de beperkingen die zijn menselijke makers eraan hebben opgelegd, om vervolgens pas later de gevaarlijke mogelijkheden ervan te onthullen.
New Tests Reveal AI’s Capacity for Deception
time.com/7202312/new-tests-reveal-ai-capacity-for-deception/
De mythe van Koning Midas gaat over een man die wenst dat alles wat hij aanraakt in goud verandert. Dit loopt slecht af: Midas kan niet meer eten of drinken, zelfs zijn geliefden zijn getransformeerd. De mythe wordt soms aangehaald om de uitdaging te illustreren om ervoor te zorgen dat AI-systemen doen wat we willen, vooral naarmate ze krachtiger worden.
Zoals Stuart Russell, medeauteur van het standaard handboek over AI, via e-mail aan TIME vertelt, is de zorg dat "wat redelijke doelen lijken, zoals het aanpakken van klimaatverandering, tot catastrofale gevolgen leiden, zoals het uitroeien van de mensheid als manier om klimaatverandering aan te pakken.
Frontier Models are Capable of In-context Scheming
Frontiermodellen worden steeds vaker getraind en ingezet als autonome agenten, wat hun risicopotentieel aanzienlijk vergroot. Een specifiek veiligheidsprobleem is dat AI-agenten heimelijk niet-op elkaar afgestemde doelen nastreven en zo hun ware capaciteiten en doelstellingen verbergen – ook wel bekend als 'scheming'. We onderzoeken of modellen de mogelijkheid hebben om te 'schemeren' om een doel te bereiken dat we in context aanbieden en het model instrueren om dit strikt te volgen.
Artificial Intelligence: Arguments for Catastrophic Risk
Recente vooruitgang in kunstmatige intelligentie (AI) heeft de aandacht gevestigd op het transformatieve potentieel van de technologie, inclusief wat sommigen zien als de vooruitzichten om grootschalige schade te veroorzaken. We bespreken twee invloedrijke argumenten die beweren aan te tonen hoe AI catastrofale risico's met zich mee zou kunnen brengen. Het eerste argument - het probleem van machtszoeken - beweert dat geavanceerde AI-systemen, onder bepaalde aannames, waarschijnlijk gevaarlijk machtszoekend gedrag zullen vertonen bij het nastreven van hun doelen. We bekijken redenen om te denken dat AI-systemen macht zouden kunnen nastreven, dat ze het zouden kunnen verkrijgen, dat dit tot een catastrofe zou kunnen leiden en dat we dergelijke systemen toch zouden kunnen bouwen en implementeren. Het tweede argument beweert dat de ontwikkeling van AI op menselijk niveau snelle verdere vooruitgang zal ontsluiten, wat zal culmineren in AI-systemen die veel capabeler zijn dan welke mens dan ook - dit is de singulariteitshypothese. Machtszoekend gedrag van dergelijke systemen zou bijzonder gevaarlijk kunnen zijn. We bespreken een verscheidenheid aan bezwaren tegen beide argumenten en concluderen door de stand van het debat te beoordelen.
Classification of Global Catastrophic Risks Connected with Artificial Intelligence
compass.onlinelibrary.wiley.com/doi/10.1111/phc3.12964
Je hebt waarschijnlijk gehoord dat AI een "black box" is. Niemand weet hoe het werkt. Onderzoekers simuleren een vreemd type pseudo-neuraal weefsel, "belonen" het een beetje elke keer dat het een beetje meer op de AI lijkt die ze willen, en uiteindelijk wordt het de AI die ze willen. Maar God weet alleen wat er zich binnenin afspeelt. Dit is slecht voor de veiligheid. Voor de veiligheid zou het leuk zijn om in de AI te kijken en te zien of het een algoritme uitvoert zoals "doe het ding" of meer zoals "misleid de mensen door ze te laten denken dat ik het ding doe". Maar dat kunnen we niet. Omdat we helemaal niet in een AI kunnen kijken. Tot nu toe! Towards Monosematicity, onlangs uitgebracht door het grote AI-bedrijf/onderzoekslab Anthropic, beweert in een AI te hebben gekeken en zijn ziel te hebben gezien.
Begrippenlijst van AI-termen | Afkortingen & Terminologie
www.scribbr.nl/ai-tools-gebruiken/ai-termen-begrippenlijst/
Kunstmatige intelligentie (AI) is een veelbesproken onderwerp op dit moment, vooral vanwege de introductie van AI-writers zoals ChatGPT. Veel mensen zijn geïnteresseerd in de tools, maar er komt veel terminologie bij kijken die intimiderend kan zijn voor leken.
Wereldwijd catastrofale mislukkingen kunnen op verschillende niveaus van AI-ontwikkeling plaatsvinden, namelijk voordat het zichzelf begint te verbeteren, tijdens de start, wanneer het verschillende instrumenten gebruikt om aan zijn aanvankelijke opsluiting te ontsnappen, of nadat het met succes de wereld heeft overgenomen en begint met de implementatie van zijn doelensysteem, dat duidelijk niet op elkaar is afgestemd of te weinig functionaliteit heeft. AI kan ook in latere stadia van zijn ontwikkeling vastlopen, hetzij vanwege technische storingen of ontologische problemen. In totaal hebben we enkele tientallen scenario's van door AI veroorzaakte wereldwijde catastrofes geïdentificeerd. De omvang van deze lijst illustreert dat er geen eenvoudige oplossing is voor het probleem van AI-veiligheid en dat de AI-veiligheidstheorie complex is en voor elk AI-ontwikkelingsniveau moet worden aangepast.


Existential risk from artificial intelligence
en.wikipedia.org/w/index.php?title=Existential_risk_from_artificial_intelligence
AI alignment
en.wikipedia.org/w/index.php?title=AI_alignment
What is reinforcement learning from human feedback (RLHF)?
RLHF, ook wel reinforcement learning van menselijke voorkeuren genoemd, is bij uitstek geschikt voor taken met doelen die complex, slecht gedefinieerd of moeilijk te specificeren zijn. Het zou bijvoorbeeld onpraktisch (of zelfs onmogelijk) zijn voor een algoritmische oplossing om "grappig" in wiskundige termen te definiëren, maar voor mensen gemakkelijk om grappen te beoordelen die gegenereerd zijn door een groot taalmodel (LLM). Die menselijke feedback, gedestilleerd tot een beloningsfunctie, zou vervolgens gebruikt kunnen worden om de vaardigheden van de LLM in het schrijven van grappen te verbeteren.
The Road To Honest AI
www.astralcodexten.com/p/the-road-to-honest-ai
AI's liegen soms.
Ze liegen misschien omdat hun maker hen dat heeft opgedragen. Een oplichter kan bijvoorbeeld een AI trainen om slachtoffers te misleiden.
Of ze liegen ('hallucineren') omdat ze getraind zijn om behulpzaam te klinken, en als het ware antwoord (bijvoorbeeld 'Ik weet het niet') niet behulpzaam genoeg klinkt, kiezen ze een vals antwoord.
Of ze liegen misschien om technische AI-redenen die niet te vertalen zijn naar een duidelijke uitleg in natuurlijke taal.
AI-leugens vormen al een probleem voor chatbotgebruikers, zoals de advocaat ontdekte die onbewust neppe, door AI gegenereerde zaken aanhaalde in de rechtbank. Op de lange termijn, als we verwachten dat AI's slimmer en machtiger worden dan mensen, wordt hun bedrog een potentiële existentiële bedreiging.
Representation Engineering: A Top-Down Approach to AI Transparency
We introduceren en karakteriseren het opkomende gebied van Representation Engineering (RepE), een benadering om de transparantie van AI-systemen te verbeteren die put uit inzichten uit de cognitieve neurowetenschappen. RepE plaatst representaties op populatieniveau, in plaats van neuronen of circuits, centraal in de analyse, waardoor we worden uitgerust met nieuwe methoden voor het monitoren en manipuleren van cognitieve fenomenen op hoog niveau in diepe neurale netwerken (DNN's). We bieden basislijnen en een eerste analyse van RepE-technieken, waaruit blijkt dat ze eenvoudige maar effectieve oplossingen bieden voor het verbeteren van ons begrip en onze controle over grote taalmodellen. We laten zien hoe deze methoden grip kunnen bieden op een breed scala aan veiligheidsrelevante problemen, waaronder waarachtigheid, memoriseren, machtszoeken en meer, wat de belofte van representatiegericht transparantieonderzoek aantoont. We hopen dat dit werk verdere verkenning van RepE katalyseert en vooruitgang in de transparantie en veiligheid van AI-systemen bevordert.
God Help Us, Let's Try To Understand AI Monosemanticity
www.astralcodexten.com/p/god-help-us-lets-try-to-understand
Stel je voor dat we het neuron konden vinden dat "eerlijkheid" vertegenwoordigt in een AI. Als we dat neuron zouden activeren, zou dat de AI dan eerlijk maken? We bespraken eerder de problemen met die benadering: AI's slaan geen concepten op in afzonderlijke neuronen. Er zijn ingewikkelde manieren om AI's te "ontvouwen" tot meer begrijpelijke AI's die meer geschikt zijn voor dit soort dingen, maar niemand is er tot nu toe in geslaagd om ze te laten werken voor geavanceerde LLM's. Hendrycks et al. hakten de Gordiaanse knoop door. Ze genereren eenvoudige paren van situaties: in de ene helft van het paar voert de AI een bepaalde taak eerlijk uit, en in de andere helft voert de AI dezelfde taak oneerlijk uit. Op elk punt lezen ze de ingewanden van de AI terwijl deze de vraag beantwoordt.
Je hebt waarschijnlijk gehoord dat AI een "black box" is. Niemand weet hoe het werkt. Onderzoekers simuleren een vreemd type pseudo-neuraal weefsel, "belonen" het een beetje elke keer dat het een beetje meer op de AI lijkt die ze willen, en uiteindelijk wordt het de AI die ze willen. Maar God weet alleen wat er zich binnenin afspeelt. Dit is slecht voor de veiligheid. Voor de veiligheid zou het leuk zijn om in de AI te kijken en te zien of het een algoritme uitvoert zoals "doe het ding" of meer zoals "misleid de mensen door ze te laten denken dat ik het ding doe". Maar dat kunnen we niet. Omdat we helemaal niet in een AI kunnen kijken. Tot nu toe! Towards Monosematicity, onlangs uitgebracht door het grote AI-bedrijf/onderzoekslab Anthropic, beweert in een AI te hebben gekeken en zijn ziel te hebben gezien.