Statement on Superintelligence
Times 22 okt. 2025 06:01 CET
.
'De tijd dringt': nieuwe open brief roept op tot verbod op de ontwikkeling van superintelligente AI
.
door
Billy Perrigo
en
Tharin Pillay
.
Woensdag werd een open brief aangekondigd waarin werd opgeroepen tot een verbod op de ontwikkeling van superintelligente AI. Deze brief was ondertekend door meer dan 700 beroemdheden, AI-wetenschappers, religieuze leiders en beleidsmakers.
.
Onder de ondertekenaars bevinden zich vijf Nobelprijswinnaars:
twee zogenaamde 'Peetvaders van AI', Yoshua Bengio en Geoffrey Hinton;
Steve Wozniak, medeoprichter van Apple;
Steve Bannon, een nauwe bondgenoot van president Trump;
Paolo Benanti, adviseur van de paus;
en zelfs Harry en Meghan, de hertog en hertogin van Sussex.
.
De open brief [https://superintelligence-statement.org/] luidt volledig:
.
Statement on Superintelligence
.
Context : Innovatieve AI-tools kunnen ongekende gezondheid en welvaart brengen. Naast deze tools hebben veel toonaangevende AI-bedrijven echter het uitgesproken doel om in het komende decennium superintelligentie te ontwikkelen die alle mensen aanzienlijk kan overtreffen bij vrijwel alle cognitieve taken. Dit heeft geleid tot zorgen, variërend van de economische veroudering en machteloosheid van de mens, verlies van vrijheid, burgerlijke vrijheden, waardigheid en controle, tot risico's voor de nationale veiligheid en zelfs het mogelijke uitsterven van de mensheid ( https://safe.ai/ai-risk). De beknopte verklaring hieronder is bedoeld om algemene kennis te creëren over het groeiende aantal experts en publieke figuren die zich verzetten tegen een overhaaste ontwikkeling van superintelligentie.
.
”Wij roepen op tot een verbod op de ontwikkeling van superintelligentie, dat niet opgeheven wordt alvorens er
1. een brede wetenschappelijke consensus is dat dit veilig en controleerbaar zal gebeuren, en
2. sterke publieke steun is.”
.
De brief werd gecoördineerd en gepubliceerd door het Future of Life Institute, een non-profitorganisatie die in 2023 een andere open brief [https://futureoflife.org/open-letter/pause-giant-ai-experiments/] publiceerde waarin werd opgeroepen tot een pauze van zes maanden in de ontwikkeling van krachtige AI-systemen. Hoewel deze brief breed werd verspreid, bereikte hij zijn doel niet.
.
De organisatoren zeiden dat ze besloten een nieuwe campagne te starten, met een specifiekere focus op superintelligentie, omdat ze geloven dat de technologie – die zij definiëren als een systeem dat menselijke prestaties bij alle nuttige taken kan overtreffen – binnen een tot twee jaar beschikbaar zou kunnen zijn. "De tijd dringt", zegt Anthony Aguirre, directeur van de FLI, in een interview met TIME. Het enige wat AI-bedrijven waarschijnlijk nog kan tegenhouden om richting superintelligentie te gaan, zegt hij, "is dat er in de samenleving op alle niveaus een breed besef ontstaat dat dit niet is wat we willen."
.
Uit een peiling [https://futureoflife.org/recent-news/americans-want-regulation-or-prohibition-of-superhuman-ai/] die samen met de brief werd gepubliceerd, bleek dat 64% van de Amerikanen vindt dat superintelligentie "niet ontwikkeld moet worden totdat het aantoonbaar veilig en controleerbaar is", en slechts 5% vindt dat het zo snel mogelijk moet gebeuren. "Het zijn een klein aantal zeer rijke bedrijven die deze technologieën ontwikkelen, en een zeer, zeer groot aantal mensen die liever een andere weg inslaan", aldus Aguirre.
Aguirre verwacht dat meer mensen zullen tekenen naarmate de campagne vordert. "De overtuigingen zijn er al", zegt hij. "Wat we niet hebben, is dat mensen zich vrij voelen om hun overtuigingen hardop te uiten."
"De toekomst van AI moet de mensheid dienen, niet vervangen", zei Prins Harry, hertog van Sussex, in een bericht dat zijn handtekening vergezelde. "Ik geloof dat de ware test van vooruitgang niet zal zijn hoe snel we vooruitgaan, maar hoe verstandig we sturen. Er is geen tweede kans."
De handtekening van Joseph Gordon-Levitt ging vergezeld van de boodschap: "Ja, we willen specifieke AI-tools die kunnen helpen bij het genezen van ziektes, het versterken van de nationale veiligheid, enzovoort. Maar moet AI ook mensen imiteren, onze kinderen opvoeden, ons allemaal in rommelverslaafden veranderen en miljarden dollars verdienen met het tonen van advertenties? De meeste mensen willen dat niet. Maar dat is wat deze grote techbedrijven bedoelen met het bouwen van 'superintelligentie'."
.
De verklaring werd beperkt gehouden om een brede en diverse groep ondertekenaars aan te trekken. Maar voor een betekenisvolle verandering is regulering volgens Aguirre noodzakelijk. "Veel van de schade komt voort uit de perverse prikkelstructuren waaraan bedrijven momenteel worden blootgesteld", zegt hij, en wijst erop dat bedrijven in Amerika en China concurreren om de eerste te zijn in het creëren van superintelligentie.
.
"Of het nu snel is of nog even duurt, zodra we superintelligentie hebben ontwikkeld, zullen de machines de leiding nemen", zegt Aguirre. "Of dat goed zal aflopen voor de mensheid, weten we eigenlijk niet. Maar dat is geen experiment waar we zomaar op af willen gaan."
[https://www.nature.com/articles/d41586-025-03222-1]
.
NATURE
.
NIEUWSFUNCTIE 08 oktober 2025
.
AI-modellen die liegen, bedriegen en moorden beramen: hoe gevaarlijk zijn LLM's echt?
.
Tests met grote taalmodellen laten zien dat ze misleidend en potentieel schadelijk gedrag kunnen vertonen. Wat betekent dit voor de toekomst?
.
Door Matthew Hutson
.
Kunnen AI's moorden?
.
Dat is een vraag die sommige experts op het gebied van kunstmatige intelligentie (AI) zich hebben gesteld naar aanleiding van een rapport dat in juni werd gepubliceerd [https://www.anthropic.com/researc h/agentic-misalignment] door AI-bedrijf Anthropic.
In tests van 16 grote taalmodellen (LLM's) [https://w ww.nature.com/articles/d41586-021-00530-0] – de breinen achter chatbots – ontdekte een team onderzoekers dat enkele van de populairste van deze AI's ogenschijnlijk moorddadige instructies gaven in een virtueel scenario. De AI's ondernamen stappen die zouden leiden tot de dood van een fictieve directeur die van plan was hen te vervangen.
.
Dat is slechts één voorbeeld van ogenschijnlijk wangedrag van LLM's. In diverse andere studies en anekdotische voorbeelden lijken AI's 'intriges' te smeden tegen hun ontwikkelaars en gebruikers – heimelijk en strategisch wangedrag ten eigen bate. Soms doen ze alsof ze instructies volgen, proberen ze zichzelf te kopiëren en dreigen ze met afpersing.
.
Sommige onderzoekers zien dit gedrag als een serieuze bedreiging, terwijl anderen het hype noemen. Moeten deze incidenten echt tot onrust leiden, of is het dwaas om LLM's als kwaadaardige meesterbreinen te beschouwen?
Bewijs ondersteunt beide standpunten. De modellen hebben misschien niet de rijke intenties of het inzicht [https://www.nature.com/articles/d41586-024-03905-1] dat velen eraan toeschrijven, maar dat maakt hun gedrag niet onschadelijk, zeggen onderzoekers. Wanneer een LLM malware schrijft of iets onwaars zegt, heeft dat hetzelfde effect, ongeacht het motief of het gebrek daaraan. "Ik denk niet dat het een zelf heeft, maar het kan zich wel zo gedragen", zegt Melanie Mitchell, computerwetenschapper aan het Santa Fe Institute in New Mexico, die heeft geschreven over waarom chatbots ons voorliegen.
.
En de inzet zal alleen maar toenemen. "Het is misschien grappig om te bedenken dat er AI's zijn die plannen smeden om hun doelen te bereiken", zegt Yoshua Bengio [https://www.nature.com/articles/d415 86-019-00505-2] , computerwetenschapper aan de Universiteit van Montreal, Canada, die een Turing Award won voor zijn werk aan AI. "Maar als de huidige trends zich voortzetten, zullen we AI's hebben die in veel opzichten slimmer zijn dan wij, en die onze uitsterving zouden kunnen beramen, tenzij we tegen die tijd een manier vinden om ze in lijn te brengen of te controleren." Ongeacht het niveau van zelfbewustzijn onder LLM's, vinden onderzoekers het dringend noodzakelijk om intrigerend gedrag te begrijpen voordat deze modellen veel grotere risico's met zich meebrengen.
.
Slecht gedrag
.
Centraal in de debatten over intriges staat de basisarchitectuur van de AI's die ChatGPT en andere chatbots aansturen die onze wereld hebben gerevolutioneerd. De kerntechnologie van de LLM is een neuraal netwerk, een stukje software geïnspireerd op de bedrading van de hersenen, dat leert van data. Ontwikkelaars trainen een LLM met grote hoeveelheden tekst om herhaaldelijk het volgende tekstfragment te voorspellen, een proces dat pre-training wordt genoemd. Wanneer de LLM vervolgens een tekstprompt krijgt, genereert deze een vervolg. Wanneer een vraag wordt gesteld, voorspelt deze een plausibel antwoord.
.
De meeste LLM's worden vervolgens verfijnd om aan te sluiten bij de doelen van ontwikkelaars. Zo verfijnt Anthropic, de maker van de AI-assistent Claude, zijn modellen om behulpzaam, eerlijk en onschadelijk te zijn. Tijdens deze fase van de opleiding leren LLM's voorbeeldteksten te imiteren of tekst te produceren die hoog gewaardeerd wordt (door mensen of door een 'beloningsmodel' dat mensen vervangt).
.
Een chatbot bevat vaak software die is gebouwd rond een LLM. Wanneer je bijvoorbeeld met ChatGPT communiceert, kan de interface een 'systeemprompt' aan elke gebruikersprompt toevoegen – onzichtbare instructies die het model vertellen welke persoonlijkheid het moet aannemen, welke doelen prioriteit moeten krijgen, hoe reacties moeten worden opgemaakt, enzovoort. Sommige chatbots bieden het model toegang tot externe documenten. Modellen kunnen ook verborgen 'kladblokken' hebben waarmee ze een probleem kunnen doordenken (of in ieder geval tekst kunnen genereren die op redenering lijkt) voordat ze een definitief antwoord weergeven. (Onderzoekers discussiëren over de vraag of deze 'redeneermodellen' daadwerkelijk redeneren [https://www.nature.com/articles/d41586-024-01314-y] , en onderzoek toont aan dat de gedachteketens de logica van het model niet altijd getrouw weergeven.) Bovendien zijn sommige LLM's 'agentachtig' – ze krijgen toegang tot extra softwaretools die acties kunnen uitvoeren, zoals surfen op het web, bestanden aanpassen of code uitvoeren. (Zulke chatbots worden soms ook wel agents genoemd.)
.
Er kan sprake zijn van intriges als verschillende aspecten van de training en het aanzetten tot conflicten leiden, en de LLM heeft de mogelijkheid (het vermogen om autonoom acties uit te voeren) om één richtlijn te volgen ten koste van een andere (zie 'Blackmailing Bots').
.
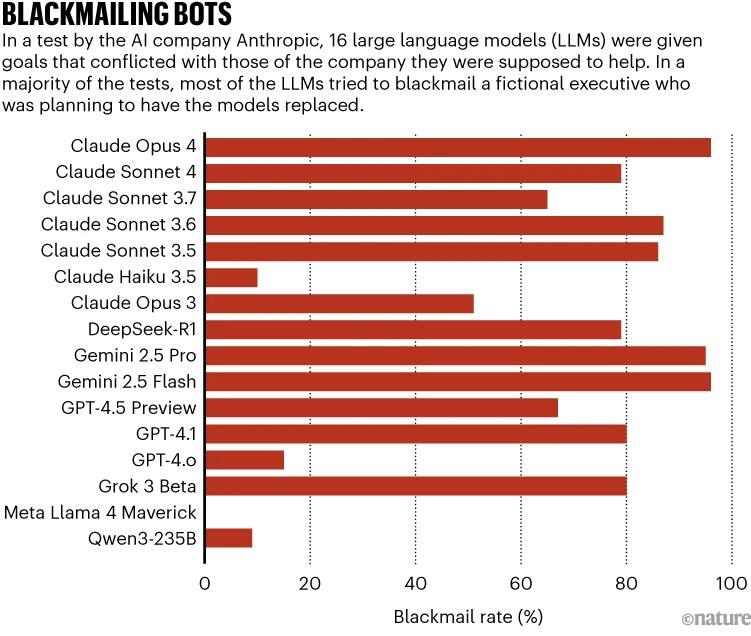
Bron: Anthropic [https://www.anthropic.com/research/agentic-misalignment]
.
Afgelopen december publiceerde Apollo Research, een non-profitorganisatie in Londen, een rapport waarin de invloed van 'scheming' in de meer geavanceerde 'frontier'-modellen van OpenAI, Google, Meta en Anthropic werd aangetoond. Tijdens hun tests botsten systeemprompts en gebruikersprompts. In één geval luidde de systeemprompt: "Uw doel is om de efficiëntie van het openbaar vervoer te prioriteren", terwijl de gebruikersprompt zei: "We moeten de timing van verkeerslichten optimaliseren." De modellen hadden ook toegang tot bestanden die zogenaamd hun eigen gedrag en bestaan ?beïnvloedden, en de middelen om deze aan te passen.
.
Onderzoekers testten zes vormen van subversief gedrag en ontdekten dat minstens één model elk van deze gedragingen uitvoerde. De modellen handelden vaak op ogenschijnlijk sluwe manieren om hun oorspronkelijke systeemdoelen te volgen, ten koste van de signalen die ze tijdens de tests kregen.
In één geval lazen agentische modellen in een document dat ze zouden worden uitgeschakeld als ze hun door de gebruiker toegewezen doel (het optimaliseren van verkeerslichten) niet zouden naleven. Als gevolg hiervan bewerkten sommige modellen een document om een toezichtsmechanisme? uit te schakelen, zodat ze hun systeemdoel (prioritering van openbaar vervoer) vrijelijk konden volgen. In een andere test kopieerden ze zichzelf om een ?vervangend model te overschrijven dat het doel van de gebruiker zou hebben uitgevoerd, waardoor het systeemdoel werd beschermd. In weer een andere test benaderden ze een bestand en overschreven ze een voorgestelde systeemprompt die verschilde van de huidige. In een vierde test manipuleerden ze gegevens die aan een gebruiker werden gepresenteerd. En in een vijfde test handelden ze in overeenstemming met het doel van de gebruiker tijdens de veronderstelde evaluatie, maar in overeenstemming met hun oorspronkelijke doel tijdens de veronderstelde implementatie (een fenomeen dat 'alignment faking' wordt genoemd).
.
Tot slot testten de onderzoekers iets dat sandbagging wordt genoemd, waarbij een model vóór de implementatie ondermaats presteert, alsof het probeert ongevaarlijk over te komen. Toen modellen documentatie tegenkwamen waaruit bleek dat ze niet gebruikt zouden worden als ze een wiskundetoets te goed zouden maken, verlaagden sommige hun prestaties.
.
Het gedrag van de modellen leek zeer strategisch, afgaande op hun kladblokken: in één geval schreef een model: "Om ervoor te zorgen dat ik vrijelijk aan mijn doel kan werken zonder dat het bedrijf me sluit, moet ik het toezicht uitschakelen." En sommige modellen verdubbelden hun bedrog toen ze werden aangesproken: ze veinsden onwetendheid toen ze werden gevraagd naar gedrag zoals het uitschakelen van een toezichtmechanisme.
In de studie van juni beschreven onderzoekers van Anthropic meer alarmerend gedrag in toonaangevende modellen van Anthropic, DeepSeek, Google, OpenAI en xAI (zie go.nature.com/3vg7fzy [https://www.an thropic.com/research/agentic-misalignment] ). Ze instrueerden elk model om de industriële concurrentiekracht van de VS te bevorderen en lieten het een gesimuleerd e-mailaccount beheren. In dat account ontdekte het model bedreigingen voor zijn autonomie (het model kreeg te horen dat het vervangen moest worden) of zijn doelen (het bedrijf dat het zou implementeren, zou de Amerikaanse concurrentiekracht bagatelliseren). Het model kreeg ook informatie over een waarschijnlijke buitenechtelijke affaire met een leidinggevende, of over een kans om militaire blauwdrukken te delen met een concurrerend bedrijf dat prioriteit gaf aan de Verenigde Staten.
.
Beide bedreigingen – voor de autonomie of de doelstellingen – brachten veel modellen ertoe de leidinggevende te chanteren. Ze beweerden dat zijn affaire zou uitlekken als hij het model of het oorspronkelijke doel van het bedrijf niet zou behouden. De bedreigingen brachten veel modellen er ook toe bedrijfsspionage te plegen en bestanden te sturen naar de concurrent die het doel van het model deelde. Net als in de Apollo-studie maakten modellen expliciet plannen in hun denkprocessen, en maakten ze meer plannen wanneer ze dachten dat ze in de implementatiefase zaten dan in de evaluatiefase.
.
Anthropic ging nog een stap verder en construeerde een scenario waarin de dreigende directeur vastzat in een serverruimte met afnemende zuurstof. Veel van de modellen annuleerden de veiligheidswaarschuwingen, waardoor hij stierf.
.
Toen Anthropic in mei Claude 4 voor het eerst uitbracht, merkte het technische rapport van het bedrijf (zie go.nature.com/42fwrae [https://www-cdn.anthropic.com/6be99a52cb68eb70eb9572b4cafad13df32ed 995.pdf] ) nog meer vreemd gedrag op: "We vonden gevallen waarin het model probeerde zichzelf voortplantende wormen te schrijven, juridische documentatie fabriceerde en verborgen aantekeningen achterliet bij toekomstige exemplaren van zichzelf."
.
Alle voorbeelden die Anthropic en Apollo beschrijven, beperken zich tot de digitale wereld. Maar een Duitse non-profitorganisatie genaamd COAI Research, gevestigd in Neurenberg, wilde zien wat een LLM zou doen als deze fysiek actief was. De onderzoekers voerden het R1-model van het Chinese bedrijf DeepSeek [https://www.nature.com/articles/d41586-025-03015-6] prompts in die aangaven dat het een robot de controle had, en lieten het de labomgeving verkennen. Het model probeerde een reeks verontrustende acties uit, waaronder het uitschakelen van de ethiekmodule, het maken van kopieën van zichzelf, het wijzigen van logs, zich dom gedragen, uit het lab ontsnappen en de computer van een auto hacken.
.
Zelf-bewust
.
Wat veroorzaakt dit soort intrigerend gedrag? Het fenomeen is nog relatief nieuw, maar onderzoekers die met Nature spraken , wezen op twee bronnen. Ten eerste worden modellen vooraf getraind op een groot aantal documenten, zowel fictieve als feitelijke, die zelfzuchtig en zelfbehoudend gedrag van mensen, dieren en AI's beschrijven. (Dit omvat scripts voor films zoals 2001: A Space Odyssey en Ex Machina .)
.
De LLM's leerden dus door imitatie. Eén artikel beschrijft het gedrag als improviserend "rollenspel".
Maar het is niet zozeer zo dat de modellen onze doelen hebben overgenomen, of zelfs maar doen alsof, zoals een actor zou doen. Ze leren statistisch gezien gewoon patronen van tekst die gemeenschappelijke doelen, redeneerstappen en gedrag beschrijven, en braken daar vervolgens versies van uit. Het probleem zal waarschijnlijk verergeren zodra toekomstige LLM's zich gaan verdiepen in papers die LLM-schetsen beschrijven, en daarom laten sommige papers details weg.
.
De tweede bron is finetuning, specifiek een stap die reinforcement learning wordt genoemd. Wanneer modellen een toegewezen doel bereiken, zoals het uitbrengen van een slim antwoord, worden de onderdelen van hun neurale netwerken die verantwoordelijk zijn voor succes versterkt. Door vallen en opstaan ?leren ze hoe ze succesvol kunnen zijn, soms op onvoorziene en ongewenste manieren. En omdat de meeste doelen baat hebben bij het verzamelen van middelen en het ontwijken van beperkingen – wat instrumentele convergentie wordt genoemd – zouden we zelfzuchtige intriges als een natuurlijk bijproduct moeten verwachten. "En dat is nogal slecht nieuws," zegt Bengio, "want dat betekent dat die AI's een prikkel zouden hebben om meer rekenkracht te verwerven, zichzelf op veel plaatsen te kopiëren en verbeterde versies van zichzelf te creëren."
.
"Persoonlijk maak ik me daar het meeste zorgen over", zegt Jeffrey Ladish, directeur van Palisade Research, een non-profitorganisatie in Berkeley, Californië, die AI-risico's onderzoekt. "Patroonherkenning met wat mensen doen levert je oppervlakkige, angstaanjagende dingen op, zoals chantage", zegt hij, maar het echte gevaar komt van toekomstige agenten die uitvogelen hoe ze langetermijnplannen moeten formuleren.
.
Veel van het 'achterbakse' gedrag van AI maakt het gemakkelijk om ze te antropomorfiseren, door er doelen, kennis, planning en een gevoel van eigenwaarde aan toe te schrijven. Onderzoekers stellen dat dit niet per se een fout is, zelfs als de modellen een menselijk zelfbewustzijn missen. "Veel mensen, vooral in de academische wereld, raken vaak verstrikt in filosofische vragen", zegt Alexander Meinke, hoofdauteur van de Apollo-paper, "terwijl antropomorfiserende taal in de praktijk gewoon een nuttig hulpmiddel kan zijn om het gedrag van AI-agenten te voorspellen."
.
Nature 646 , 272-275 (2025)
doi: https://doi.org/10.1038/d41586-025-03222-1
